|
Technologies Applied C# .NET Framework XML ADO.NET HTTP Handlers RSS |
[Editor’s Note: This article was originally published on the Logical Expressions Computor Companion site. Due to its technical nature, it is being given a new life at Nerdy Musings.]
This article is about how you can program an RSS feed for your Web site using C# and the .NET framework.
If you look at the menu bar of this Web site, you’ll see that there is a small orange RSS button on the right-hand side. That button takes you to the Logical Expressions RSS home page. The RSS home page describes each of the feeds we offer and includes links (the orange XML buttons) to the RSS documents themselves. This article describes the technology that dynamically generates those RSS documents directly from information that is stored in a database.
Why RSS?
To understand the purpose of the code I’m going to demonstrate, it helps to understand the basics of RSS. Depending upon who you ask, RSS is an acronym for Rich Site Summary or Really Simple Syndication. (See what happens when you let software developers come up with names for things?).
For a more general discussion of RSS, check out this Q and A article. Basically, the purpose of RSS is to give you a way to watch for new content from a Web site without having to visit the site or clutter your inbox with email notifications. If the Web site offers an RSS feed, you can subscribe to that feed instead, and let your RSS reader notify you when new content is available. An RSS reader is specialized software that knows how to locate and read the XML data that describes the site’s content. RSS is rapidly becoming the preferred method for acquiring Web content because it is a "pull" technology that puts you in complete control of when and how you receive content.
RSS readers vary widely in features and implementation. Some readers work within your email program or your browser. Others stand alone. As with most things, an Internet search will give you plenty of alternatives to choose from (just search for "RSS reader").
RSS Is an XML Document
XML is at the heart of an RSS feed. In fact, you can easily build an RSS feed for your site manually just by creating an XML document that follows the RSS standard.
The down side to building RSS feeds by hand is that you have to maintain the XML file yourself every time your site’s content changes. If you have a dynamic site, particularly one that draws its content from a database, then what you really want is a tool that will update the feed for you.
That is the problem we faced with Computor Companion and its sister publication Logical Tips. Our editor wanted an RSS feed for the sites, but she didn’t want to muck around with XML every time they changed. (The Logical Tips site is updated weekly…and the editor said "no way.") If we can build Web pages dynamically, why can’t we do the same with an RSS feed? Well, the answer is we can, and we did.
To get a feel for what an RSS document looks like, here’s an example of a simple one that came from the Logical Tips Web site:
<rss version="2.0"> <channel> <title>Logical Tips</title> <link>http://www.LogicalTips.com</link> <description>Computing tips and musings</description> <language>en-us</language> <item> <title>Just Turn It Off</title> <description>Why meeting with people who refuse to turn off their cell phones is pointless.</description> <link>http://www.LogicalTips.com/LPMArticle.asp?ID=355</link> <pubDate>4/17/2004 11:00:13 AM</pubDate> <guid isPermaLink="true">http://www.LogicalTips.com/LPMArticle.asp?ID=355</guid> </item> <item> <title>Dealing with Header and Footer Weirdness</title> <description>Avoid aggravation by deactivating the Same as Previous button.</description> <link>http://www.LogicalTips.com/LPMArticle.asp?ID=356</link> <pubDate>4/17/2004 11:02:18 AM</pubDate> <guid isPermaLink="true">http://www.LogicalTips.com/LPMArticle.asp?ID=356</guid> </item> </channel> </rss>
Figure 1: Sample RSS XML Document
As you can see, the RSS document is actually very simple. It consists of an RSS root node, a channel node, and a variable number of item nodes. The channel node describes the source of the content, and the item nodes describe individual resources provided by the channel. As I said earlier, it wouldn’t be too hard to write this document by hand. Of course, if you regularly publish several articles on a weekly basis, the manual approach becomes a bit of a grind.
Automating the Feed
I was tasked with producing an RSS feed for Computor Companion and Logical Tips. Of course the next request was, while I was at it, couldn’t I just make the feed work for our other Web publications? After all, they all use the same underlying publication software (the Logical Web Publisher) and database structure. Well, sure I could!
Consequently, my requirements included the need to host RSS feeds for several sources. The easiest way for me to do that was to create a separate Web site that provides access to all the RSS feeds we offer. That approach would let me put the software that generates the feeds in one location and avoid having to modify all of the affected Web sites. Thus was born the subdomain "rss.LogicalExpressions.com."
Because I need to process requests for multiple channels, I needed a way to configure each channel and control how the channel’s item links are built. I used XML configuration files called "profiles" for that purpose.
The profiles live in a folder that is not under the Web site root, so they aren’t visible to the Web. This is desirable because the profiles may contain sensitive information, like database connection strings that include login parameters.
For the software project, I decided to use Microsoft .NET, mainly because of one very cool feature: HTTP handlers. With an HTTP handler, I can intercept requests for a specific document or document type (by extension) and dynamically assemble the XML reply from the most current information available in the database. Other technologies can do the same thing, of course, but for me they weren’t any simpler to implement.
To put the whole process into perspective, here’s a summary of what happens when a subscriber requests one of our RSS feeds:
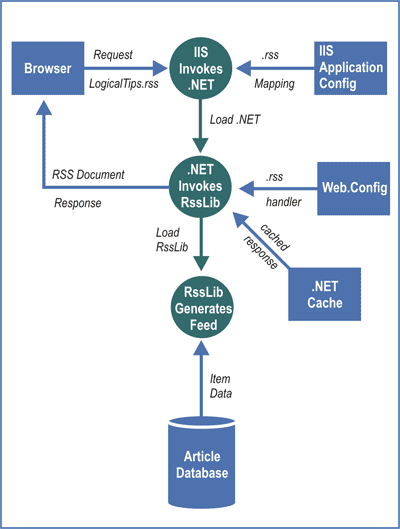
Figure 2: RSS Request Processing
- The client browser or RSS reader requests an RSS document from the site. For example: http://rss.LogicalExpressions.com/LogicalTips.rss.
- IIS sees the .rss file extension and invokes .NET to process it. This is something you have to configure in IIS, and I’ll show you how to do that shortly.
- Based on information in the Web.Config file, .NET knows to invoke RssLib (my HTTP handler) to process the request. (That is another thing I’ll show you how to set up.)
- RssLib checks for a cached copy of the RSS document. If it exists, RssLib sends the document back to the browser and terminates. If the response has not been cached (or it expired), then RssLib continues.
- RssLib reads the channel profile and retrieves information about how to build the RSS document.
- RssLib merges information from the profile with item data from the appropriate article database to build the RSS document.
- RssLib caches the RSS document and sends it back to the browser.
Building an HTTP Handler
Now that you have the big picture, I can go into detail about how RssLib works. I’ll explain the process from request to response, as I did in the overview diagram. First, I’ll cover the Web server configuration, since IIS initially handles the request.
The folder structure for this project on the Web server is simple:
RssLib Profile Web bin images Include
I created a top-level folder to contain everything related to the RssLib project, with a folder for the channel profiles and the Web site under that. The Web folder is the root folder of the Web site in IIS, so the profiles are not directly accessible through HTTP.
The Web folder includes my images and Include utility folders as well as a bin folder for the RssLib application DLL.
An interesting aspect of using an HTTP handler is that the browser request can ask for a file that doesn’t physically exist under the Web site. For example, you won’t find a file under the Web root called "LogicalTips.rss." Instead, IIS sends all requests for .rss files to the RssLib assembly, and RssLib writes the response from memory.
But how does IIS know to pass on the rss file requests? The answer is in the Web application configuration. If you open IIS and display the properties of your Web site, you’ll find a Configuration button on the Home Directory tab, which brings up the Application Configuration dialog. The first tab shows the file mappings for your site, which is where you tell IIS what to do with rss file requests.
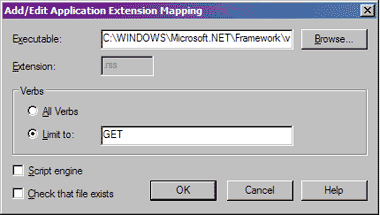
Figure 3: Application Extension dialog screen shot.
The easiest way to set up a new extension is to copy the executable path from an existing .NET mapping and create a new mapping with it. For example, you could copy the .NET worker process path from the aspx mapping and paste it into a new mapping for rss files. Figure 3 shows what the rss mapping looks like on my system. Notice that I unchecked "script engine" and "check that file exists," which are checked by default. You don’t need the scripting engine, and as I said before, IIS won’t find a physical file that matches the browser request. The only HTTP verb you need to support for rss requests is "GET."
At this point, all you’ve done is tell IIS that it needs to hand rss file requests off to .NET. You still haven’t told .NET how they should be processed once it receives them. That’s the next step.
To hook your handler up to a file extension through .NET, you add a section to the Web.Config file in the root folder of your Web application. Here’s an example that shows how I associated RssLib with rss file requests:
<?xml version="1.0" encoding="utf-8" ?> <configuration> <appSettings> <add key="profileFolder" value="C:RssLibProfile" /> <add key="cacheTimeout" value="15" /> </appSettings> <system.web> <httpHandlers> <add verb="*" path="*.rss" type="LEI.RssLib.RssHandler, RssLib" /> </httpHandlers> </system.web> </configuration>
Figure 4: Sample Web.Config
The salient part of the file at this moment is the httpHandlers section. I’ll talk about the appSettings section later on.
The httpHandlers "add" tag tells .NET to send all rss file requests (verb="*" path="*.rss") to the RssHandler class in the RssLib assembly (type="LEI.RssLib.RssHandler, RssLib").
Now all you have to do is build the handler! For the following discussions I chopped out the relevant sections of code. For a complete listing of the handler, click the link at the bottom of this page.
An HTTP handler is nothing more than a simple class library with at least one class that implements the IHttpHandler interface. The interface has just two members: the ProcessRequest method and the IsReusable property.
IsReusable tells .NET whether or not instances of your class can be safely pooled and reused. RssHandler returns true because it doesn’t maintain any state that would interfere with its reusability.
The ProcessRequest method is where all the fun stuff happens. The .NET worker process passes you a reference to the request’s HTTP context, which gives you access to the Request and Response objects as well as the other standard elements of the context.
Checking the Cache
The first thing RssLib does when it receives the request is check to see if the response has already been assembled and cached from an earlier request. Caching in .NET couldn’t be simpler: you just use the built-in Cache object, which is accessible through the context reference:
string fileName = Path.GetFileName(context.Request.Path);
string cachedChan = context.Cache[fileName] as String;
if( cachedChan == null ) {
// Perform validation and build the response here.
// Cache the response:
double cacheTimeout;
string appCacheTimeout = ConfigurationSettings.AppSettings["cacheTimeout"];
if( appCacheTimeout == null )
cacheTimeout = 15;
else
cacheTimeout = double.Parse(appCacheTimeout);
context.Cache.Insert(fileName, cachedChan, null
, DateTime.Now.AddMinutes(cacheTimeout)
, TimeSpan.Zero);
}
Figure 5: Caching Responses
The code above peels the requested file name off the query string and tries to retrieve a cached response with the same name. If it doesn’t get back a string object, then it builds the response and caches it before exiting.
When you cache an object with the Cache object’s Insert method, you should specify a timeout period. When your cached item times out, the Cache object discards it and returns a null reference on your next request for that item. I use a default cache timeout of 15 minutes, but I allow for an override to come from the Web.Config file, which takes me to the next subject.
Reading Application Settings
The .NET framework gives you a nice built-in facility for dealing with application configuration settings. The System.Configuration namespace includes the ConfigurationSettings class, which exposes a static method for retrieving configuration settings from Web.Config.
If you look back at the Web.Config sample (figure 4), you’ll see an appSettings element with two "add" child elements. The two add elements define key/value pairs that identify the location of my channel profiles (profileFolder) and my cache timeout override (cacheTimeout).
Figure 5 shows how RssHandler uses ConfigurationSettings.AppSettings to retrieve the cache timeout value. The value comes back as a string, so I converted it to the double value required by the Cache object’s Insert method.
Reading the Channel Profile
If RssLib fails to find the response in the cache, it has to build a response. The first step in building the response is to retrieve information from the channel profile, so RssHandler verifies that the required channel profile exists:
// Verify that the profile folder has been configured:
string profileFolder = ConfigurationSettings.AppSettings["profileFolder"];
if( profileFolder == null ) {
context.Response.StatusCode = 404;
context.Response.End();
return;
}
// Verify that you have a profile for the requested feed:
string profilePath = profileFolder + "\" + fileName;
if( !File.Exists(profilePath) ) {
context.Response.StatusCode = 404;
context.Response.End();
return;
}
RssChannel chan = new RssChannel(profilePath);
RssHandler gets the location of the channel profiles from Web.Config using AppSettings, as I described earlier. To that folder, it appends the file name that was requested on the query string. Note that the profile name could have been something completely different from the query string file name. I could have named the profiles with an xml extension and mapped the query string file name to them, but I decided to just keep the rss extension for convenience.
If RssHandler runs into any difficulties, like being unable to get the profile path or discovering that the requested profile does not exist, it just behaves as if the requested file was not found on the server and responds with an HTTP 404 (file not found) error.
Finally, RssHandler instantiates an RssChannel object and passes the profile name on its constructor. RssChannel and RssItem are helper objects that encapsulate the details of RSS channels and items.
Before I get into the details of how the helper objects use the profile to build the RSS document, it makes sense to look at a sample profile:
<?xml version="1.0"?>
<RssProfile>
<Title>Logical Tips</Title>
<Link>http://www.LogicalTips.com</Link>
<Description>Computing articles and tips</Description>
<Language>en-us</Language>
<ItemConnection>(OLEDB Connection String Goes Here)</ItemConnection>
<ItemSql>(Database select statement goes here)</ItemSql>
<LinkFormat>http://www.LogicalTips.com/LPMArticle.asp?ID={0}</LinkFormat>
<GUIDFormat>http://www.LogicalTips.com/LPMArticle.asp?ID={0}</GUIDFormat>
<GUIDIsPermanent>true</GUIDIsPermanent>
</RssProfile>
Most of the configuration elements in the profile relate to the channel. These elements are mostly copied into the RSS document as-is.
RssLib uses the ItemConnection and ItemSql elements to retrieve information about each item from the database. RssLib doesn’t care what database you use or how you identify and retrieve the latest items: it just cares about the information you return in your SQL statement.
To properly build item elements in the RSS document, your SQL statement needs to return the following information (in the order listed): unique identifier, title, summary, and publication date.
RssLib uses the LinkFormat and GUIDFormat elements to assemble the "link" and "guid" elements in the response RSS document. Note that these profile elements are format strings with the placeholder "{0}" for the article’s unique identifier.
In the RSS document, the link element tells the RSS reader how to navigate to the article and the guid element tells the reader how to uniquely identify the article. These values are frequently the same because the link is often a perfectly good unique identifier. Additionally, the guid element can be used to provide a permanent link to the item, as indicated by the profile’s GUIDIsPermanent element.
Okay, so back to RssChannel. In its constructor, RssChannel saves the passed profile name in an instance variable and invokes its own Load method:
public RssChannel(string profilePath) {
_profilePath = profilePath;
Load();
}
The Load method does all the work of reading the profile and the database to retrieve the information regarding the channel and its items:
private void Load() {
_items = new ArrayList();
XmlDocument profile = new XmlDocument();
// The profile is an xml document that provides configuration
// data for the feed. Load the file into an XmlDocument object:
try {
profile.Load(_profilePath);
}
catch (Exception e) {
HttpContext.Current.Response.Write(string.Format("<p>{0}: {1}</p>"
, e.Message, _profilePath));
return;
}
// Set channel properties from the profile:
_title = profile.SelectSingleNode("/RssProfile/Title").InnerText;
_itemConn = profile.SelectSingleNode("/RssProfile/ItemConnection").InnerText;
_itemSql = profile.SelectSingleNode("/RssProfile/ItemSql").InnerText;
_linkFormat = profile.SelectSingleNode("/RssProfile/LinkFormat").InnerText;
_guidFormat = profile.SelectSingleNode("/RssProfile/GUIDFormat").InnerText;
// (see full listing for other channel properties)
// Retrieve items from the database:
OleDbConnection conn = new OleDbConnection(_itemConn);
IDbCommand cmd = new OleDbCommand(_itemSql);
try {
conn.Open();
cmd.Connection = conn;
IDataReader reader = cmd.ExecuteReader();
while( reader.Read() ) {
RssItem thisItem = new RssItem(reader, _linkFormat, _guidFormat);
_items.Add(thisItem);
}
reader.Close();
reader.Dispose();
conn.Close();
}
finally {
conn.Dispose();
}
}
The channel profile is a standard XML document, so RssChannel can use an XmlDocument object to load and read it.
One of the profile elements has the connection string for the database (ItemConnection), and another provides the SQL statement that retrieves current items (ItemSQL). RssChannel uses those values to open an OLE DB connection, allocate a command object, and execute a data reader.
As you may recall, the LinkFormat and GUIDFormat profile elements contain a format string that will be used to assemble the URL of the items.
For every item row in the data reader’s result set, RssChannel instantiates an RssItem object, and passes the reader down to the RssItem constructor along with the link format and GUID format:
internal RssItem( IDataReader reader, string linkFormat, string guidFormat ) {
string itemId;
itemId = reader[0].ToString();
_title = reader[1].ToString();
_description = reader[2].ToString();
_pubDate = reader[3].ToString();
// The linkFormat argument provides the URL of the
// item's document.
_link = string.Format(linkFormat, itemId);
// The guidFormat argument provides the string that uniquely identifies
// the item for RSS readers.
_guid = string.Format(guidFormat, itemId);
}
The RssItem constructor pulls data out of the result set by position, and assumes that the identifier for the item came back in the first column (column 0). It assembles the link and GUID URL’s from the channel profile’s format strings and the item identifier.
At this point, the construction of the RssChannel and all of its RssItem objects is complete. RssHandler has assembled everything it needs to know to create the RSS document.
Assemble the Response Document
Once the helper objects are constructed, RssHandler calls the GetResponse method of the RssChannel object to generate the RSS response document:
cachedChan = chan.GetResponse();
The GetResponse method uses an XmlDocument object to assemble the RSS response. See the GetResponse method in the full listing for the code that does this. The logic performs very simple XML document manipulation.
Sending the Response to the Browser
After RssHandler gets the response document from the cache or assembles it from scratch, sending it to the browser is a trivial task:
context.Response.ContentType = "text/xml"; context.Response.Write(cachedChan);
RssHandler sets the content type to "text/xml" to explicitly state the kind of data it is returning. This is generally a good idea when the type of data you are returning (XML) is not normally associated with the file extension of the original request (rss) through a MIME file type.
Conclusion
I hope you enjoyed learning about how to create an RSS feed. If you plan to create your own feed, you can probably adapt a lot of the code I demonstrated here, even if your business requirements are considerably different. As I said in the beginning, RSS is nothing more than a specially formatted XML document.
This article showed you how to create an HTTP handler and build a properly-formed RSS document with data dynamically obtained from a database through ADO.NET. It’s interesting to see how many useful techniques can come out of such a small chunk of C# code.
Happy coding!
